Growing calls for data privacy spurred by the passage of GDPR and Google’s recent decision to nix third-party cookies from its Chrome browser has put conversational AI in the spotlight as a potential privacy concern. A recent survey by the Pew Research Center found that 79% of U.S. adults are “very concerned” about how companies use their data, while 81% feel that the risks of companies collecting their data outweigh the benefits. While consumers feel uneasy about companies surveilling them, they are also concerned about the potential for their data to be stolen by a third party in the event of a security breach.
Why do conversational commerce platforms collect personal data?
Chatbots, voice assistants, guided selling assistant, IVRs, and other conversational commerce platforms collect data for a dual purpose: one is to train the machine learning algorithms that power them to comprehend a wider range of natural language commands with the highest possible accuracy, which can only be achieved by continual learning. For example, Amazon and Google have hired subcontractors in the past to transcribe and annotate a minuscule percentage of voice messages to improve the performance of their voice assistants, but the recordings are not associated with user accounts and are essentially anonymous.
The second purpose is to parse unstructured data for consumer insights that enable companies to provide a personalized customer experience by better understanding what their customers want.
In fact, companies can achieve both objectives without ever needing to store their customers’ personal data. What matters is the content of these conversations, not the participants. Even customer segmentation can be done using contextual data that groups people of similar interests and purchasing habits without associating unique identifiers. Consequently, many conversational AI vendors have rolled out solutions that are GDPR-compliant—meaning the customer has the option of opting out, reviewing, and deleting their data—while still enabling businesses to extract voice of customer insights from anonymized conversation data.
3 ways conversational commerce platforms can adapt to protect consumer data privacy:

1. GDPR compliance and privacy by design
Many companies have responded to the passage of GDPR by offering a default “opt-out” for the sharing of personal information. This means that businesses cannot transfer and process a customer’s data unless they grant their consent. Under GDPR law, personal information doesn’t only pertain to personally identifiable information like name, email address, or date of birth, but also web data, including location, IP address, and browsing history. Furthermore, once the purpose of the data has been served, it must be deleted immediately.
At the start of a conversation, chatbots should provide users with a clear-cut privacy statement that outlines what data is collected and how the organization will use it. This means redesigning the chat panel and including a permanent link to the privacy policy in the main menu, while also writing reply messages asking for the user’s consent to data sharing.
Companies should also prepare chatbot responses to FAQs around their privacy policy to ensure greater transparency—for example, “How long will you store my data?” Rather than simply referring customers to a dense privacy document filled with legalese, engaging in a dialog with a chatbot provides a friendlier customer experience.
Chatbots and voice assistants should also give customers the option of deleting, reviewing, and updating their data through menu options or using natural language commands. If a customer wants to download a transcript of their conversation with a chatbot, they should be able to do so by typing “download my conversations” or some other command into the chat, or by selecting from a menu of options listed under a dedicated privacy tab.
Users should also be able to stop their data from being processed for direct marketing purposes, with the process ceasing as soon as the request is received. Opt-out procedures should be simplified accordingly. Don’t require someone to submit a request in writing and mail it to the company P.O. box—that’s not real data transparency. Enable a simple, seamless digital opt-out where the request is received immediately on the back-end.
2. Using AI to redact or delete sensitive information before it’s stored
People reveal an unbelievable amount of information in conversations, including their individual preferences, views, opinions, feelings, and inclinations. While these sound like gold to a marketer, much of this information is superfluous for data analysis purposes.
For example, a customer who contacts their virtual pharmacy requesting antidepressants might reveal that a family member recently passed away. What’s more, customers often try to predict what information is needed for authentication purposes and may supply you with their telephone number, address, or date of birth unprompted at the start of a conversation. Suddenly, the organization has someone’s personal data and a duty of care to protect it.
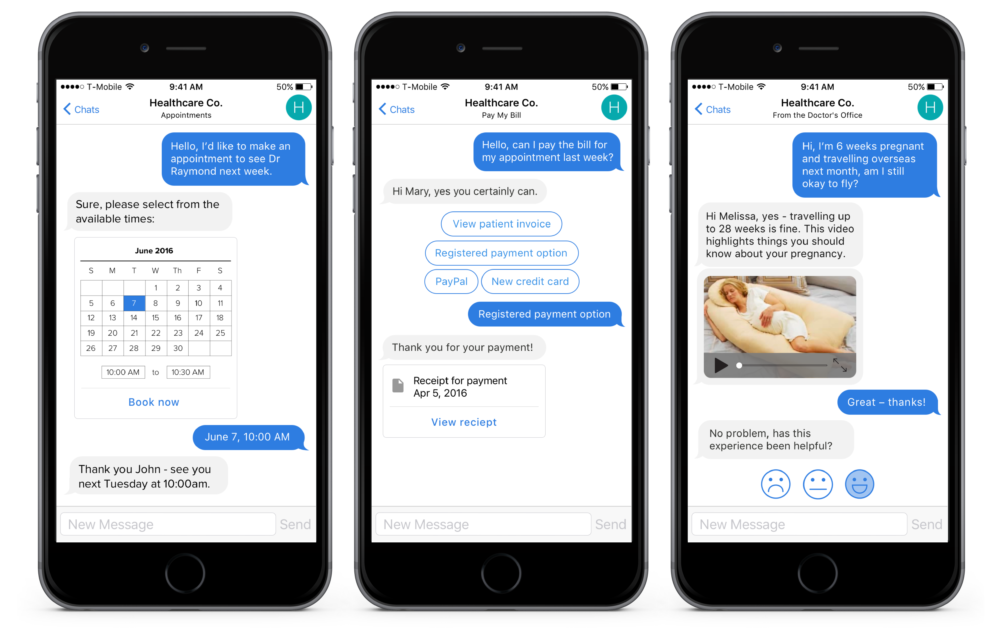
When it comes to virtual pharmacies, telehealth services, and personal finance chatbots, the nature of the personal information customers reveal during the course of a conversation is typically much more sensitive than in a typical e-commerce setting.
Web servers and messenger platforms that run chatbot services store different kinds of logs, including access, error, and security audit logs. Conversational AI solutions must provide redaction controls that prevent sensitive data from being stored in logs either by deleting the information or replacing it with random text (known as pseudonymization). Natural language understanding models can be trained to recognize personal data such as names, IP addresses, and dates of birth.
Customers may need to provide their personal information at certain junctures of the conversation, such as for authentication purposes or to fulfill an order. Other times, they may inadvertently share personally identifiable information such as their social security number. Redaction controls should extend to both use cases.
This anonymization approach allows organizations to retain parts of their conversation data that afford real consumer insights without tracing it back to individuals. Therefore, customers are identified by their interests and purchasing habits (eg: “this buyer is a gamer who likes fantasy games and uses an Xbox”) rather than their metadata.
3. Deploying end-to-end encryption for all conversations
That being said, companies still have a legitimate need to store their customer’s personal information, such as their credit card number and address for authentication and billing purposes. Personal data is most vulnerable after it is stored when a company’s computer networks and servers are susceptible to a cyberattack, but data in transition can also be tampered with. During an attack, hackers can steal personal information or sell it on the dark web.
End-to-end encryption is crucial to ensure the whole conversation is encrypted. Data encryption is the process of encoding or scrambling information by converting the original representation of the information, known as plaintext, into an alternative form known as ciphertext. Article 32 of the GDPR specifically requires that companies take measures to pseudonymize and encrypt personal data. If you use an external chatbot service such as Facebook Messenger, Telegram, or Slack, stick to channels that support data encryption. On the backend, store all personal data in a dedicated user object that is encrypted and separated from other data.
Finally, most companies store chatbot logs to see which inquiries the bot successfully and unsuccessfully responds to, and which ones require a handoff to a live agent. In this case, use a separate set of AI training data to retrain the chatbot, and keep it separate from chat log data. This results in greater security because it takes the customer completely out of the equation.